当你想要评估一个函数在一个分布P上的期望,但是无法从这个期望直接采样,于是从另一个分布Q去采样,然后计算在P上的期望,因为是从Q上进行采样的,所以需要一个权重去修正。这种修正的方法就叫重要性采样,下面将详细介绍其数学原理和应用
数学本质
重要性采样是一个“加权”的过程:用分布 Q产生的数据,去估计分布 P的期望值。 那个权重,就叫重要性权重(Importance Weight)。
在统计学中,我们想求函数 f(x) 在真实分布 p(x) 下的期望 Ex∼p[f(x)],但我们只能从另一个分布 q(x) 中采样。
根据期望的定义,我们可以做一个简单的数学变换:
Ex∼p[f(x)]=∑p(x)f(x)
=∑q(x)q(x)p(x)f(x)
=Ex∼q[q(x)p(x)f(x)]
结论非常优雅:你可以从 q(x) 中采样,但要把每次得到的结果 f(x) 乘以一个比例 q(x)p(x)。这个比例就是重要性权重。
- 如果 p(x)>q(x),权重 >1,说明这个样本在目标分布中更重要,要放大它的影响。
- 如果 p(x)<q(x),权重 <1,说明要缩小它的影响。
看下面的可视化图:
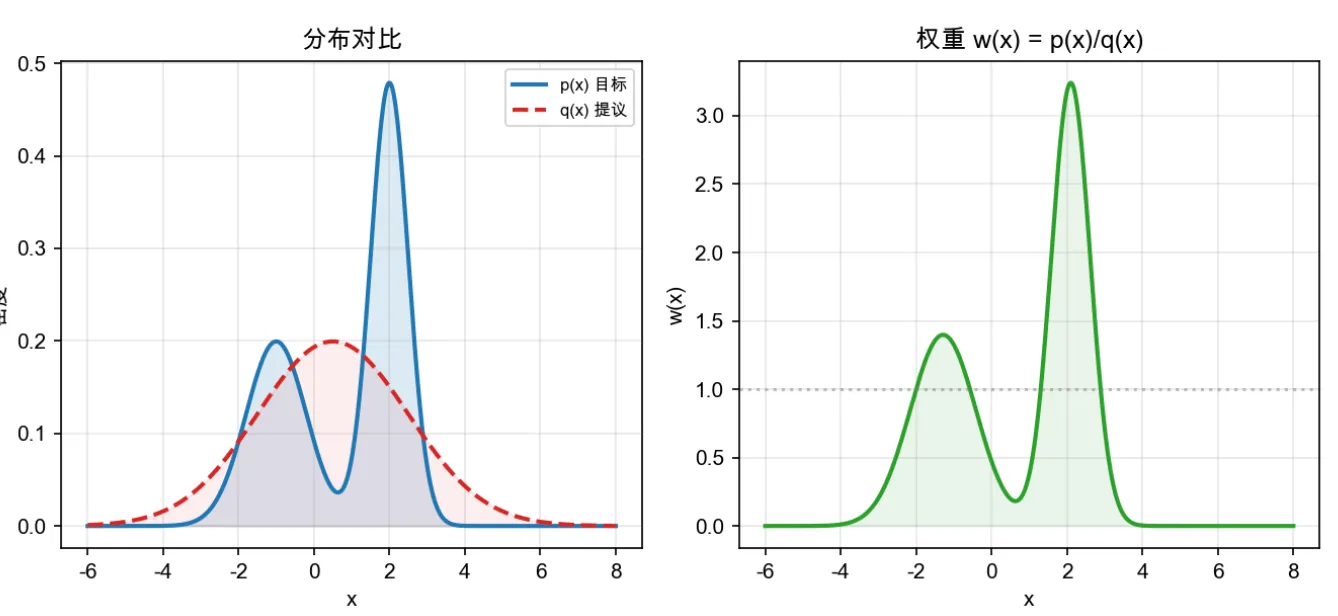
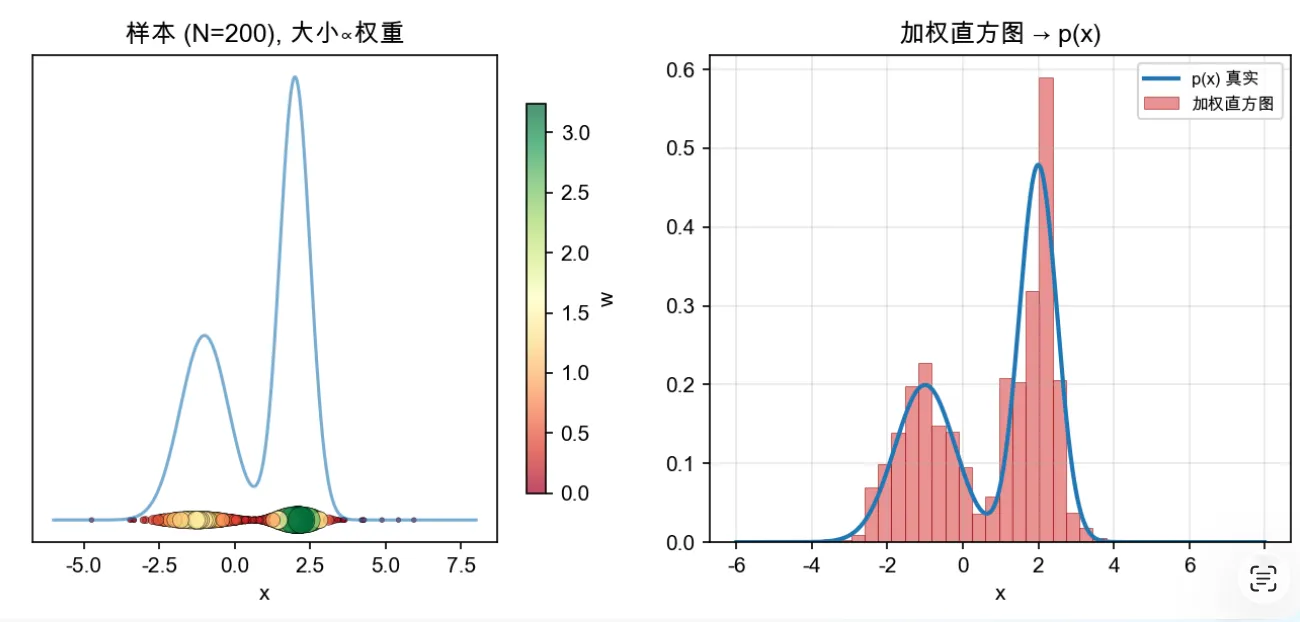
p(x) 的peak附近会拉高权重,让采样的时候增加影响。通过下面的采样图可以更直观感受:
强化学习中的应用
在 RL 中,我们有两个策略:
- 目标策略 π (Target Policy):我们正在训练、想要评估的策略。
- 行为策略 μ (Behavior Policy):在环境中实际与环境交互、收集数据的旧策略。
我们想计算目标策略 π 跑完一局(一条轨迹 τ)的期望总回报 J(π)。但手头只有行为策略 μ 跑出来的轨迹数据。
一条轨迹 τ=(s0,a0,s1,a1,...,sT) 在策略 π 下发生的概率是:
Pπ(τ)=P(s0)t=0∏Tπ(at∣st)P(st+1∣st,at)
(初始状态概率 × 每一步的动作概率 × 每一步的环境状态转移概率)
根据重要性采样,我们需要计算权重 ρ=Pμ(τ)Pπ(τ):
ρ=Pμ(τ)Pπ(τ)=P(s0)∏μ(at∣st)P(st+1∣st,at)P(s0)∏π(at∣st)P(st+1∣st,at)
分子和分母中的初始状态概率 P(s0) 和 环境的状态转移概率 P(st+1∣st,at) 是完全一样的,它们被约掉了
ρ=t=0∏Tμ(at∣st)π(at∣st)
强化学习中,我们通常不知道环境的动态模型 P(st+1∣st,at)(比如超级马里奥游戏内部的物理引擎)。重要性采样让我们完美绕过了环境模型,只需要知道“新策略采取该动作的概率”除以“旧策略采取该动作的概率”连乘起来即可。
有了 ρ,我们就可以用旧策略收集的回报 G,去更新新策略了:Eπ[G]=Eμ[ρ⋅G]。
数学目的与工程结果的统一
- 统计学中: 用分布 Q 的数据,加权评估分布 P 的期望。
- 在 PPO 中: 分布 Q 就是旧策略(收集数据时的策略 πold),分布 P 就是新策略(正在通过梯度下降更新的神经网络 πθ)。
我们想知道:“如果用我现在的新策略去玩游戏,期望得分会是多少?”
如果没有重要性采样,唯一的办法就是把新策略放到环境里去跑一局(这就导致每次更新都要重新采样,数据利用率极低)。
因为重要性采样保留了“评估另一个分布的期望”的数学能力,它在 RL 工程上自然而然地产生了巨大的红利:数据复用(Sample Efficiency)。所以,增加数据利用率不是它目的的改变,而是其数学属性在现实中的直接变现。
现在我们来看公式:
LIS(θ)=πold(at∣st)πθ(at∣st)At=rt(θ)At
这个公式告诉神经网络:“新策略 πθ 去评估一下旧策略做的动作。如果旧策略觉得是个好动作(At>0),而且你现在做这个动作的概率比旧策略还要高(rt>1),那我就给你更高的奖励得分。”
At是就策略在采样时期的优势评估值。